By the time you have read this sentence, Visa would have processed 25,000 txs/second , while a rollup would have processed only 4,000 txs/second. Why such a stark difference? Because transactions on the visa network are authorized individually but processed in a bulk. As a result, whatever transactions reach the server are settled as they occur and verified later.
But when it comes to TPS on rollups, the scenario is different because every connected node has to agree to the read/write on/ to the blockchain for finality. That said, the lesser the transaction sizes, the faster for these nodes to verify and include the same in the block, improving the TPS & throughput.
At the moment, by abstracting the operational environment in the form of data availability, execution, consensus and settlements, rollups have reduced the transaction size dramatically from 109 bytes to 12 bytes increasing TPS on rollups. But for meeting any further scalability fitting into the narrative of 100k TPS to compete with Visa, data compression on rollups must enhance without diluting verifiability and decentralization.

The Missing Piece of the Puzzle To Hyper Scalability:
What we don’t have effectively till now is, consistency of DAS, Account Abstraction and Compression
As we have already seen that rollups have achieved scalability which has dwarfed L1s by storing data on an alternative layer and making them readily available as and when required for verifiability at a fraction of a cost. But when it comes to scaling to 100k TPS, on rollups, the need is to find ways to further squeeze data beyond using DA.
How could that data squeezing happen?
This can only happen when there’s a gateway allowing further transaction pruning. DAS or Data Availability Sampling is a good way forward which is still not available on blobs but it does give us a way forward. And when this has been implemented, the capacity on the blobs can be increased in the near future as claimed through the image below.. As you can see
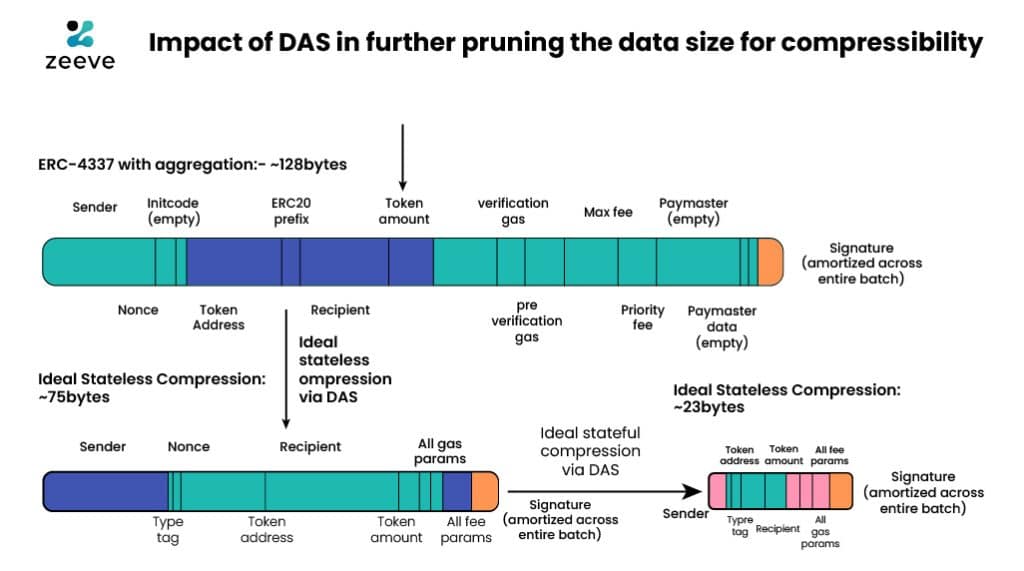
Source: Vitalik Buterin’s website
when EIP- 4337 + with aggregation techniques have been put into use, they have reduced the ideal state compression size to 23 bytes. However, upon bundling the same with EIP-4844, where DAS comes into picture through a PeerDAS model, even smaller byte sizes below 12 bytes can be achieved by first compressing the UserOp on the client side.
It will then be followed by an account abstraction technique where the smart-contracts can query commonality. This commonality can further compress the data for internal scaling within the rollups. In this model, through account abstraction, the rollup environment can evaluate repetitive transactions and abstract the same space by allowing a new form of transaction to occupy its place for high TPS on rollups. Such a pruning of data can significantly reduce the load on the network and improve its efficiency.
In a recently concluded airdrop, a project used batching and data grouping with run-length encoding compression, such a technique reduced the data size through a linear data compression by 61.68%.
If such a method is applied for internal scaling within a rollup environment that uses blob data for data availability, it is possible to reach 13888.88 transactions per blob size and with 3 blobs per block on L1, reaching the 100k TPS with rollups doesn’t look like a far cry considering that blobs lesser transaction sizes using DAS would include more blobs per block to increase TPS on rollups for internal scaling..
With the capacity of including 512 KB of data per block instead of only 100 KB on an average that Ethereum allows at the moment, one can only contemplate lower Tx size can free up space for blobs to include more transaction and increase the internal rollup capacity to reach new heights.
Parallelization: Mimicking the Toll Lanes for High TPS on Rollups
Why toll gates do not have a single lane for allowing the vehicles to pass? If you do so it will lead to a lot of work for a single operator to process. Likewise, we have already discussed the data pruning which was an enigma code to crack for rollups has been somewhat achieved through data compressions and EIP-4844. But none of that would even matter until and unless rollups have the technology in place to allow simultaneous transaction processing across all levels.
However that can only happen when the rollups environment is built like a toll-gate, instead of a single passage. Vitalik Buterin, the founder of Ethereum says that Dencun Upgrade has increased the capacity of the rollups, undoubtedly through low fee data availability. But in the absence of an environment that can process millions of transactions and not succumb to network pressure, the battle is half won. EIP-648 is the missing piece to find and deploy.
How will EIP-648 solve the problem of parallel processing?
An example will help you better understand this concept. Imagine a queue at a theater. All the movie goers are scattered with the attendant at the kiosk having no idea who would watch what; thereby creating a lot of waiting time for the viewers/movie goers. .
Now, replace the same scenario with the kiosk where the attendant knows who would be willing to watch which movie. In such a situation, the attendant at the Kiosk can simply see the head count and put a single query, 20 tickets for Avengers movie and the movie goers quickly get those tickets without having to share details every single time to the attendant. Such an arrangement can not only handle limitless scalability but also provide a better user experience.
The rollups can do the same for the users through parallelization where the rollup environment defines ranges in the RLP list. For example,
Introduce a new type of transaction (following same general format as #232):
[2, network_id, startgas, to, data, ranges]
Where ranges is an RLP list, where each value in the list is an address prefix, representing the range of all addresses with that prefix. That is, for example:
For a Range function from 0-99, the rollups smart-contract can abstract specific categories like segregate all transactions below 20 from an address XXggsjjklslqqsjsjsjsjsj to 1 gshslkshlkshklqshjkls
Now, the rollups can segregate all such groups and put in parallel processing based on the call functions. So, the rollups can define such range functions for NFTs to utility tokens transcations to simply swap and burn.
As a result, selectively segregation without disrupting latency occurs in the rollup environment to improve throughput and scalability where the users can define starting_gas_height, finishing_gas_height,
start_gas ,
total_gas_used, and the rollup environment quickly eliminates all other transactions that do not follow these guidelines at the sequencer node. The ideal movie scenario that was discussed in the example above.
This practice allows all the transcations in the EVM to be processed in parallel because through blobs you have already solved the pressing gas problem and through parallelization, you simply ensure that the network is able to remain sustainable despite low returns to investment to secure the network for high TPS on rollups.
So, we see that modularity has worked for rollups in its initial stages but now it is high time to upgrade for mass level adoption. To achieve 100k TPS on Rollups, the ecosystem should progress at all fronts from reducing the pricing to making the experience better for users like TradFi minus drawbacks. Parallelization, protodanksharding and account abstractions have simply improved the state of the TPS on rollups. In the near future, advancements in technology will make rollups ready for industry level adoption and that’s where the need for a technology partner could help you blend with the change.
Launch a hyper scalable OP/ZK rollup with Zeeve RaaS
Zeeve’s Rollups-as-a-Service (RaaS) simplifies your objective of launching your own custom Layer 2 or Layer3 rollup through its low code deployment tool for all the leading rollups. You can launch your very own ZK or Optimistic Rollups using Zeeve’s RaaS. Alongside this, Zeeve’s years of experience in the industry has helped build meaningful valuable partnerships with more than 40 integration partners in the rollups space. Users can get the advantage of quickly integrating their solutions in their rollup environment. Zeeve also provides important rollups components like scalable nodes, RPCs, data indexers , block explorers, testnet faucets, cross-chain bridges, and more that you need for building your custom rollup.
For support, you can always connect with us since we are an ISO 27001 certified and SOC 2 Type service provider to help launch your rollups today.