The Graph network is already a substantially grown, powerful, and new-age data indexing network. However, the core developer team at Graph continues to improve its existing capabilities, taking Subgraph’s blockchain data indexing capabilities to the next level. Their recent addition is Substream-powered Subgraph, firehose-enabled technology for faster data indexing, complete with high-performance and query parallelization in a streaming-first method.
This article explains all the essential details about Substreaming-powered Subgraph, including basics working, key features, setup method, and more.

What are Substreams-powered Subgraphs?
Substream-powered Subgraphs are advanced data indexing solutions designed to accommodate the existing capabilities of The Graph Network. It provides data consumers or web3 applications with a familiar GraphQL API with Substream modules integrated as data sources. However, to deploy a Substream-powered Subgraph, developers need a Firehose-enabled node. Further, they must write custom Rust modules to compose relevant data streams for specific extraction.
Substream supports data indexing from all kinds of blockchain networks like Ethereum, Polygon, zkSync Era, Optimism Goerli, and Arbitrum at lightning speed. Substream is an independent blockchain data indexing technology now supported on the Graph network’s Subgraph. Since the Streaming-based Subgraph is new, there is some confusion around it. Let’s address them:
What exactly is a Substream-based Subgraph :
- A streaming-first technology powered by gRPC, StreamingFast Firehose, and Protobuf..
- Framework for offering highly cacheable and remote, parallelizable code execution.
- Ecosystem for supporting the development of higher-order composable modules and individual modules.
Who needs Substreams-powered Subgraphs?
Substream-powered Subgraphs are mostly suited for web3 applications such as gaming apps, DEXs, wallets, or aggregators that require seamless access to accurate, up-to-dated blockchain data. Here, standard Subgraphs can also be a feasible option, but it takes around time for syncing blockchain data. Substream subgraph reduces this period considerably. That means if your project needs extremely faster indexing time, then Substream is preferred. Otherwise, Subgraphs are the way to go.
A good example is Uniswap-v3 Substream-powered Subgraph. Uniswap which has built Subgraph to be leveraged for its liquid staking solution– Lido. Traditionally, Uniswap has to wait for around 2 months (1440 hours) to sync the data. Now, with Substream, the process is being completed in 20 hours- This shows a 72x increase in speed.
How do Substreams-based Subgraphs enable faster data indexing?
Substream subgraphs have a range of next-gen features and functionalities for allowing rapid-fast blockchain data indexing. The main feature is Firehouse, which replaces the traditional linear indexing model of RPC-based Subgraphs with stream-based data queryability. Further, Firehose is optimized to tackle the data indexing challenges created by EIP-4444. Developers utilizing a Substream-powered subgraph can leverage the fastest data synchronization, which is more than 100x better. To enable this, Substreams breaks the data pipeline into four states:
- Extract (using Firehouse)
- Transform (using Substream-based Subgraph)
- Load (to Postgres database)
- Query (serving users’ queries)
Subgraph does the above process with its three core components— subgraph.yaml, mappings, and schema.graphql.
Below is the graphical representation of Subsreams Graph’s various modules that allow it to extract blockchain data:
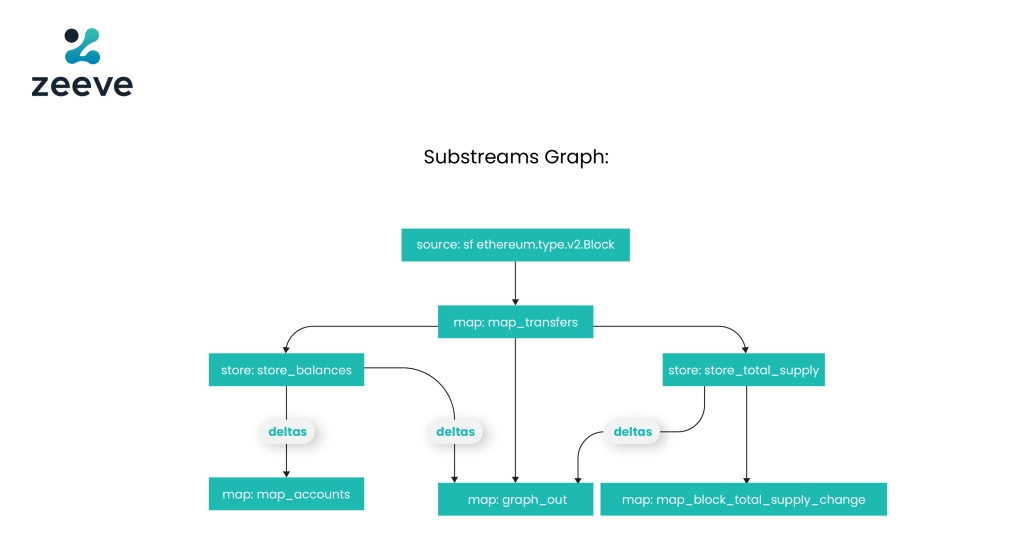
- First, there’s the source– block, which is the input for the map_transfers module.
- One map module receives data, maps filters, and feeds the data to the downward modules– store_balances and store_total_supply.
- At the end, the graph_out module will feed the data to the Subgraph store., The rest of the two modules, map_accounts and map_block_total_supply_change, show how to use store modules, which means they are functions of the store.
That was all about Streaming Subgraph’s modules and working. Now let’s discuss its main features that enable faster data indexing:
Support for RPC Poller:
StreamingFast has introduced a novel technology for data extraction called RPC poller. This feature is now supported on Streaming-powered Subgraphs, complementing Substream, The Graph network, and Firehose’s existing capabilities, allowing chains to index data 10x faster. To achieve this, the RPC poller uses standard JSON-RPC endpoints that are defined through Ethereum execution API with no requirement for additional tooling.
Advanced parallelization technique:
Substream-based Subgraph utilizes a unique parallelization technique for enabling fast and efficient processing of blockchain data, providing filtered data to different data stores and real-time applications.
Streaming-fast approach:
Substreams inherit all the benefits from StreamingFast Firehose, such as low-cost caching, high throughput processing, archiving blockchain data, and cursor-based reorgs handling. Firehose is an independent service that extracts data seamlessly as per various chain-specific extensions, for example- Ethereum’s eth_calls.
Horizontal scaling features:
With the ability to be horizontally scalable, the Substream-powered Subgraph can reduce the overall data processing time by adding more computing power or advanced machines.
Composable Substreams modules:
Unlike RPC-Subgraph, which listens to blocks, Substream-powered Subgraph uses Rust modules that offer hooks to the Substream’s data execution engine. Each module can have more than one input, either in the form of a map, store, block, or clock object coming from the blockchain’s data source.
Data modeling and integration:
Substream-based Subgraph utilizes Google Protocol Buffers in various programming languages. Protocol Buffers or protobufs are basically APIs for data models specific to be used for the different blockchains. While writing the manifest for your Subgraph, you need to add references to the protobufs that will serve the module.
Benefits of Substreams-powered Subgraphs for Web3 Developers
Substream Subgraphs offers a list of benefits for developers using The Graph Network, including:
- Lightening fast indexing– Substreams optimize the data indexing speed through large-scale clusters running parallel (like BigQuery). Plus, it uses a prototype created by StreamingFast– Sparkle that can reduce the sync time to approximately 6 hours and scale across all the different chains’ Subgraphs.
- Easy composability– Developers can stack modules like LEGO blocks while also being able to build upon the community modules, refining the blockchain’s data.
- Sink anywhere: Sink data to your preferred place– for example, you can add it to PostgreSQL, MongoDB, Kafka, subgraphs, flat files, or simply in Google Sheets.
- Programmability: Substream offers you the flexibility to customize and automate the data extraction, such as transformation-time aggregations for modeling the data outputs for multiple sinks.
- Benefits of the Firehose: As obvious, the Substream-powered Subgraph has all the benefits of Firehose, including the lowest latency, higher availability, no polling, data sinking to flat files, and the option to use the best data model.
Subgraphs and Substream-powered Subgraph– which one should you choose?
When choosing between Substreams and Subgraphs, you must know their main differences, which are mentioned below:
- Substreams modules are written in RUST, whereas Subgraph manifests are written in AssemblyScript.
- Substream initiates ‘stateless’ requests via gRPC. Subgraphs require persistent deployments.
- Substream requires a gRPC connection, allowing you to have full control of the output message, while Subgraph uses GraphQL calls.
- With Substream, you do not get a long–term database for storage, whereas Subgraph stores all the data persistently in Postgres.
- Substream allows data to be consumed in real-time with its fork-aware model. Speaking about Subgraphs, they can be consumed via GraphQL and polling for ‘real-time’.
Now that you know the basics of Substream vs. Subgraph, here’s a simple explanation to help you choose one:
Both the standard Subgraph and streaming-based Subgraphs offer distinct benefits, tailored for specific use cases. Like, Substreams offer extremely fast data indexing through parallelization and live-streaming capabilities for both the historical and real-time data requirements. If you index the same historical data with Subgraphs, it will take much time, maybe months. However, building a Substream-powered Subgraph is difficult. You have to setup a whole new set of infrastructure, write rust modules with node-js, and manage firehose-enabled blockchain nodes.
With Subgraphs, you just need to write manifest, do mappings, add schema and your Subgraph is ready for deployment. That’s because subgraph fetches data from archived nodes via JSON-RPC method, which is easy for most developers. For a conclusion, we can say that Substreams and Subgraphs, both are suitable based on your use case-specific requirements, hence analyze all your requirements well to make an informed decision.
Launch your Subgraph easily with Zeeve
Zeeve offers a comprehensive stack for seamless deployment of custom Subgraphs on its enterprise-grade infrastructure. Whether you want to build a custom, single-use Subgraph or you want to deploy your subgraph on a shared infrastructure for per-subgraph pricing model— Zeeve offers you flexibility in deployment options. As required, you can opt for general-use or application-specific Subgraphs.
Since Zeeve offers managed service, you do not have to do the heavy lifting of managing Graph nodes, delegating tokens to indexers or curators, or programming modules or manifests. Everything will be handled by Zeeve. With Zeeve’s hosted service, Kunji Finance– a crypto investment platform has witnessed benefits like high-speed data indexing, hassle-free infrastructure management, streamlined operations, and a major reduction in subgraph deployment and management costs.
For more information on how Zeeve is simplifying Subgraph-based services or to discuss your requirements, talk to our experts in blockchain data indexing. You can drop your queries via email or schedule a one-on-one call for a detailed discussion.